
JANOG45 Meeting 参加レポート 2
tech_team インターネットの技術 他組織のイベント参加することになった経緯
2019年10月より、JPNICでの調査研究に携わっている五島と申します。大学院情報系学科の修士課程に所属する学生で、専門は機械学習理論です。
JPNICでは未割り振りIPアドレスの実態調査に取り組んでいます。12月頃から対外的に発表できそうな成果が蓄積できているのですが、現場のネットワーク運用者が集まるミーティングの場で直接情報交換することで、今後の研究にさらに有益な知見を得るため、JANOG45 Meetingに参加してきました。以下本記事では、その参加報告をさせていただきます。
筆者は機械学習理論を専門としているため、今回のJANOG45で参加してきたセッションの中から、その観点で興味深かった一つを選んで紹介いたします。(以下には機械学習およびセキュリティに関する専門的表現が含まれます。)
『まあまあ簡単まあまあお手軽異常検知』について

こちらはシスコシステムズ合同会社の石川章史さんによる発表でした。内容は、ご自身がSOCメンバーとして蓄積してきた経験則/知見を基に、DNSクエリに含まれる「不正と見られるクエリ」を機械学習で検知するシステムを設計するという試みです。学習モデルはディープラーニングで、特徴量としてクエリ内のドメイン名に含まれるドットの数、アルファベットの数、TLDの文字数などを使用していました(モデルの概要は図1.1参照)。
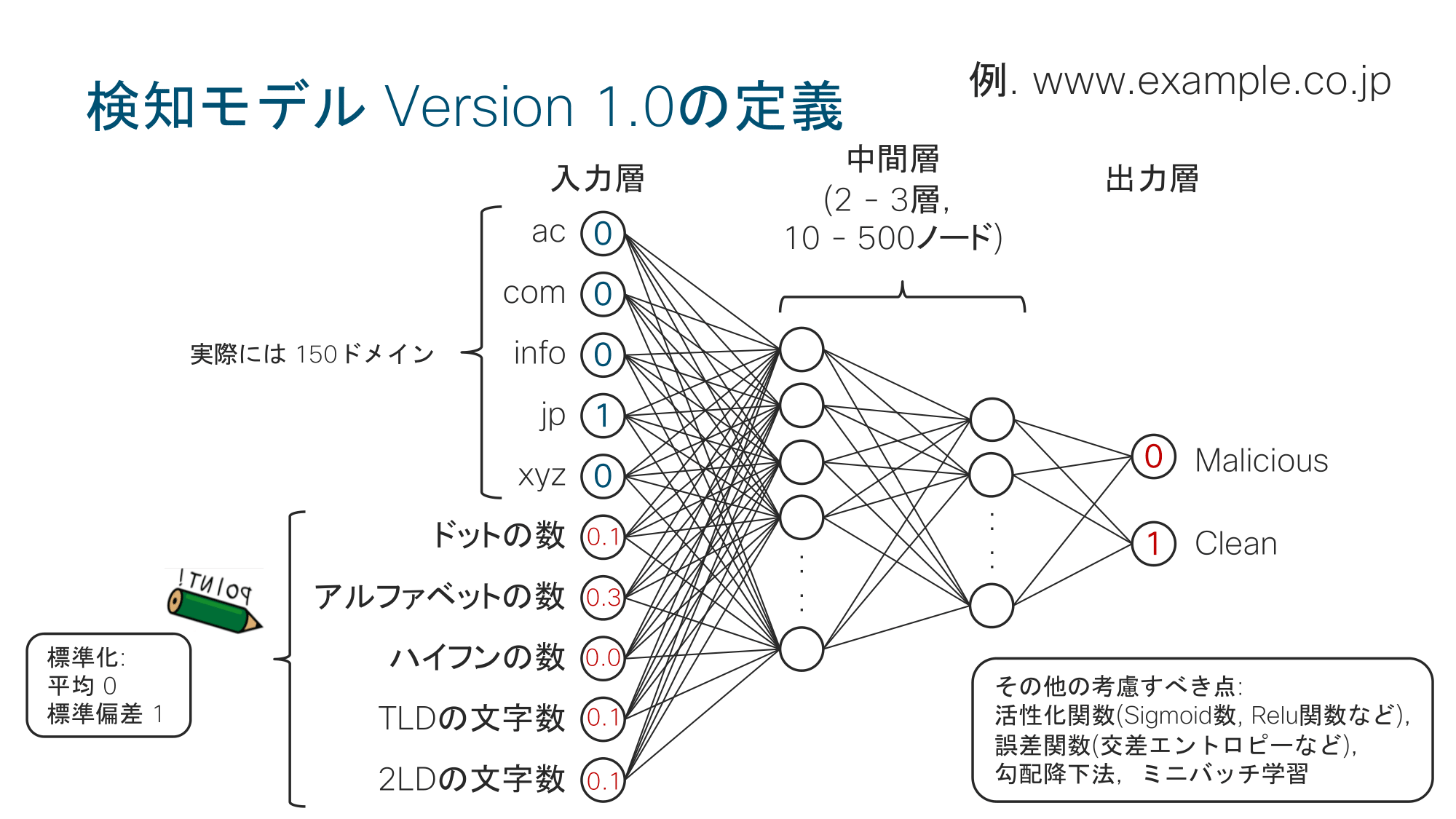
教師データはbenign/malicious合わせて約5000件を公開データから収集し、さらに自前で収集したbenignデータを追加して学習に用いていました。実装にはPythonおよびディープラーニングでよく用いられるTensorFlow、 Keras、 ChainerそしてReNomといったライブラリを使用したそうです。
発表では、SOCという現場だからこそ得られる知見がいくつか紹介されました。経験則として、アクセス頻度の低い特定のTLDや、やたらにハイフン”-“が多く含まれるドメイン名、さらにjpドメイン名のように信頼性の高いTLDを装ったもの、そしてDGA(ドメイン生成アルゴリズム)によって生成されたことがうかがえる文字列を含むドメイン名が「怪しい」とされるということでした。以上のような、SOCとしての経験を通して重要だと考えられる特徴量を用いてディープラーニングを適用すると、テストデータ約563件(教師データとして収集されたうちの約10%)に対する混同行列は図1.2のようになったそうです。

図1.2からは、一部の特徴的な文字列(上述の、ハイフンが多い/アクセス頻度の低いTLDを含むなど)の検知が可能となった一方で、誤検知 (FP、 FN) すなわち濡れ衣と見逃しが多かったことがわかります。この問題に関して、セキュリティ業界における誤検知に対する姿勢としては、「見逃しを増やしてでも濡れ衣は可能な限り減らす」という方針があるということでした。
以上を総合すると、まだ検知精度は十分とはいえないものの、インシデント調査のきっかけとしては役に立つのではないか、という結論でした。ただし、maliciousデータの収集が困難であり、結果として教師データの分布が不均衡になってしまうという懸念をお話しされていました。同様に、benignデータもそれに見合った量・質が必要ということでした。したがって、benign/malicious問わず、現実のデータの収集にコストがかかることによって、下調べ段階の学習にも時間を要するという現状がわかりました。
これに対して筆者からは、ディスカッションの時間に「まあまあ簡単まあまあお手軽」を軸にすえる限りにおいては、DA (data augumentation) を使ったアプローチが可能ではないかという提案をしました。DAとは、不均衡データのうち少数派 (今回は2値分類のため) を擬似的に水増しあるいは多数派の一部のみを用いた学習データセットを作成するという手法です。今回は分類対象のデータがドメイン名であり、したがって形式は文字列型であるため、線型補完などを用いたデータの擬似生成というアプローチが果たして適切かどうかの判断は現場の専門家の方にお願いしたいということを申し添えて、ディスカッションは終了しました。
さらに追加するならば、新規ドメイン名の作成にも流行り廃りやその時々の定石となる手法があるはずであり、攻撃の傾向も推移すると考えられます。例として、東京オリンピック2020の公式サイトなどを狙った類似ドメイン名の作成によるフィッシング攻撃がすでに指摘されています (大学とJPRSによる共同の調査研究結果: https://nsl.cs.waseda.ac.jp/tokyo2020/。また関連研究として、ドメイン名中の文字の外形的類似性を利用したURL偽装攻撃について調査されています: https://nsl.cs.waseda.ac.jp/presented-a-talk-imc19/。
以上のように、攻撃手法に対する調査・研究は進められており、今後もSOCの現場において機械学習がどのように活用されていくのか注目しております。
冒頭でも述べましたように、筆者個人は情報系学科の修士課程に所属する学生です。普段のゼミにおける議論では様々な手法や技術/ツールが登場するものの、学術の場を離れたところではどのように受け取られているのかはあまりわかっていませんでした。そうした意味で、現場の技術者の方と直接やりとりができるこのセッションは筆者にとって有意義だったと考えています。
最後に今回の出張全体への所感と、今後の調査結果の発表について簡単に述べます。
全体への所感と今後について
普段の大学研究室の生活では、出張といえばまずは学会、あったとしてデータコンペやハッカソン系のイベントが多い中、今回はかなり特殊な体験ができました。また、Meeting自体以外にも楽しめるものがたくさんあった札幌滞在となりました。ご協力/ご指導いただいたJPNICの皆様、ありがとうございました。
冒頭で述べましたJPNICで取り組んでいる研究については、対外的な発表の場として2020年2月12日よりオーストラリアのメルボルンで開催されるAPRICOT 2020に参加することになりました。資料提出直後にCommitteeチェアから直接メールで連絡があり、新規性がないのではないかなどのご指摘を受け、内心冷や汗をかいておりました。それでも訂正と資料改訂を重ね、いつ査読結果がわかるのか聞いたところ、ちょうどJANOGに向けて羽田を出発する日だということでした。と、ここまではあまり心地のよいスタートではありませんでしたが、新千歳空港に着陸してすぐスマートフォンの機内モードを解除した途端にAcceptedの文字が入ったメールが届きました。今回のJANOG参加で心の準備もできましたので、良い報告ができるよう努めて参ります。